Much has been written about microservice architecture as seen in blogs here (http://microservices.io/patterns/microservices.html) and here (http://martinfowler.com/articles/microservices.html). This is a promising approach to deal with large scale integration of software so that it is easily maintainable, high performing, and scalable. Although the approach has some concrete foundation, there are some serious practical considerations that involve scalability and performance that one must take into account in order to ensure good SLAs. Anyone who has tuned high-end platforms understands that this approach is not straightforward.
Consider the industry over the last 15 years as I briefly review emerging software engineering trends that are important to give context to the move toward microservices. Today, microservices and functional programming trends are prominent in many software development discussions, where these concepts of software engineering patterns were born out of empirical findings and limitations of object oriented programming (OOP) and service oriented architectures (SOA).
Both OOP and SOA had challenges and failed to comprehensively address programming techniques that deal with agility of the codebase with minimal brittle effect to the scalability and performance of the runtime application kernel. (Developers like myself understand the meaning of “brittle effect.”) From a programming perspective we saw the rise of OOP largely through data abstraction, encapsulation, inheritance, and polymorphism. However, large-scale systems became difficult to develop, and with the famous debacle of the earlier EJB specification, a new concept emerged based on dependency injection / inversion-of-control (IoC), which was largely popularized by the Spring framework. This trend involved code that looked more like services, which were functional pieces of code that were well encapsulated to have a well-defined interface with sets of inputs and outputs, and the various service relationships and dependencies injected by the container. During this time we saw less emphasis on inheritance, but more on what functionality a developer is trying to deliver to the caller with scalability and maintainability. Likewise, we saw the concept of encapsulating the functionality into a well-defined set of services.
During the same time, the phenomenon of SOA was well popularized but there was not a clear and distinct best practice for a concrete implementation of this. Many implementations did succeed, but some were very difficult and failed. Some had services that were just too large and monolithic, while others had too many smallish services (almost microservices like) that it became difficult to achieve good performance. The concept of SOA was there, but designers and implementers failed to understand the full lifecycle of the service and its granularity and scalability impact on other services, and therefore paid a huge price during implementation.
It remains difficult to define what a service is, as this largely depends on the developer and how well they understand the end-to-end lifecycle of the service they are offering. Part of the problem is that the developer lacks full understanding of the underlying infrastructure services – for example, when to scale up or scale out, what the cost of scaling out is, and how it impacts response time. On the other hand, infrastructure service providers do not have insight into application components and how they should be best mapped.
Consider the following important practical aspects when building new microservices-capable platforms, or in some cases platform as a service (PaaS) deployments. Issues such as fragmented horizontal scalability, licensing considerations, performance, and code deployment flexibility.
1. Fragmented Horizontal Scalability
I came across a customer that had implemented the concept of microservices where they defined 25 REST services as part of their services layer. Front end web applications would connect to these REST services through a back end middleware/services layer to conduct transactions. After close examination of the call paradigm, we found that the vast majority of their transactions, approximately 90% of transactions would require traversal of all 25 REST services to complete an end-to-end business transaction. On the first day that the platform was launched they decided to have a one-to-one relationship between REST services and the JVM onto which it was deployed. Thus, RESTService1 was deployed on JVM1, and so on through RESTService25 deployed on JVM25.
Much of the influence of the one-to-one approach came from various writings of how microservices should be implemented, which unfortunately disregards the performance aspects and the overall total cost of ownership of the underlying infrastructure as well as licensing of the software components/containers.
On that first day when they launched the platform, they needed 25 REST services, and therefore 25 JVMs. Each of the JVMs had a heap size of 1 GB, so the total heap space across all JVMs was 25 GB. After being in operation for a few months they discovered that they needed to scale out by an additional 5 GB. Because the functionality of their scale-out architecture required a minimum of 25 JVMs (25 REST services) they were forced to add another 25 JVMs, or an additional 25 GB. Over time this pattern led to an environment made up of 400 JVMs, each with 1 GB heap, across 16 physical hosts.
Figure 1 shows on the right the 400 JVMs that constitute this platform across 16 physical hosts. The left hand side illustrates how the load balancer interacts with the 400 REST services. The green arrow shows the completion of an entire transaction within one host, while the blue arrows show the potential of bouncing to another host to complete a transaction. Clearly this many network jumps can hurt response time and overall performance. The paradigm almost always assumes that everything is remote and makes a remote service call, when in fact 90% of the time this is not the case.
Figure 1. Load Balancer Interaction with the 25 REST Services

Therefore, one issue is the need to deal with the ping pong effect on the completion of a transaction. One approach is to consolidate all of the REST services into one JVM heap space, and scale out to accommodate the 400 GB worth of heap. This naturally leads to larger JVMs, but it also has the distinct advantage that most or all of the calls will be local.
Figure 2. Highly Tuned High Performance Service
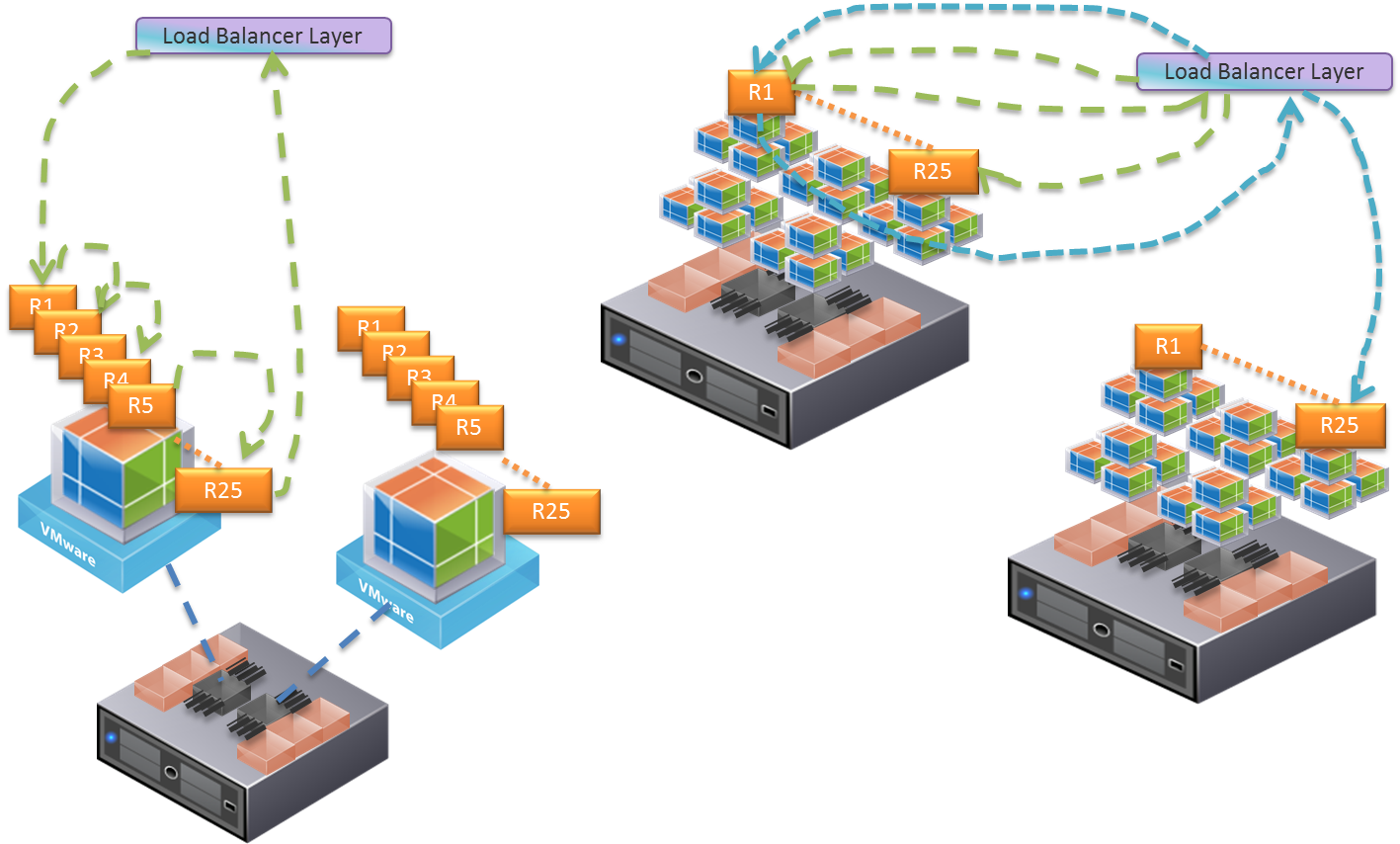
Figure 2 shows how we can deploy the 25 REST services all onto one JVM, and scale out based on how many JVMs we actually need to fulfill the 400 GB heap requirement. The basic setup is 2 VMs running on a host, with 1 JVM per VM. In this deployment paradigm when a transaction reaches the JVM at RESTService1 the call continues all the way through to RESTService25, all within the same JVM and thus the same heap space. We tested this and found a 3x improvement in response time as compared with the old single REST service per JVM approach of Figure 1 (also shown at the right of Figure 2).
The VM sizes are no doubt NUMA optimized. I will write about NUMA optimization in an upcoming blog, but for now I show in Table 1 a deployment calculation for 400 GB and 800 GB in case there is a future need to extrapolate for traffic growth.
In this table we show how we collapsed the original 400 JVMs down to 12 JVMs of 34.56GB heap size.
Table 1. NUMA Optimized VM and JVM Size for 400 GB and 800 GB Platforms

In this approach we still had 12 JVMs, which is plenty of scale-out capability. The downside is that you have very large JVMs that can potentially lose more data than with the original paradigm. However during a close examination of the old fragmented system we found that this was a false assumption. In fact, many times a JVM would crash and take down a service, for example, RESTService3. If a transaction had completed its transit through RESTService1 and RESTService2, it sat hanging, waiting for RESTService3. The code did not have retry logic, which is not necessarily the best approach, but it can work. What we found is that although the remaining REST service JVMs were running (the remaining 24), they could not complete transactions, so they were indeed up, but useless. In the case of the refined deployment where we show all 25 REST services consolidated into one heap space, the entire transaction set can be rolled back cleanly, failed over, or made redundant. By contrast, if you try to do that with the fragmented scaled-out approach, you have to chase down which JVM and REST service is currently performing or holding up the transaction.
This comes with the need to understand how to tune and size large JVMs, which is an area where we have done much research with our customer base and have been producing and publishing the various approaches.
Figure 3 shows each section of the JVM and the VM with various sizes.

Figure 4 shows a snippet of the JVM options used, mostly using a combination GC of CMS in old generation and ParNewGC in young generation. In an upcoming blog I will explain each one of these JVM options in detail.
Figure 4. High Performance Service JVM with Various GC Options

2. Licensing Considerations
If you plan to proliferate microservices, note that each time you spin a new JVM there might be additional licensing costs – for example, if you need a license for each application server instance. In our case we were able to consolidate from 16 physical hosts down to 6. This had a direct impact on reducing the application server license cost, operating system license cost, and power consumption on the order of 60%.
Consider the practical limitations of licensing costs, as the majority of application servers are licensed by CPU cores, and having licensed a NUMA node or CPU socket you want to use up as much as possible of the memory attached to those CPU cores. Otherwise, you will have paid for licensing the usage of that memory without utilizing it. Although having larger JVMs will quickly get you the largest returns, you can also stack up multiple smaller JVMs instead. However in that case, every new JVM instance comes with its own overhead and needs additional CPU core cycles to fulfill the heavy GC cycles.
After a JVM has been launched and it has consumed the initial overhead, it continues to scale vertically very well without proportionally tracking an increase in CPU utilization. We specifically experimented with this using the GemFire in-memory database and noticed that a cluster of 8 very large JVMs would outperform a cluster of 30 smaller JVMs having the same heap size. We also conducted other performance studies that show the vertical scalability of JVMs using web applications, back in 2010.
3. Performance – How Much to Scale Up or Scale Out
More recently we tested this assumption yet again on a PaaS installation, comparing 2 JVMs of 2 GB each with 4 JVMs of 1 GB each. We found that the 2 JVM case outperformed the 4 JVM case by 26% with better response time and 60% less CPU utilization.
Figure 5 shows the response time chart. The blue lines represent Scenario-1 with 4 JVMs using 1 GB heap each as a scale out, while the red line is Scenario-2 of 2 JVMs using 2 GB heap each showing a good mix of scale up and scale out. In Figure 5 we see that Scenario-2 has 26% better response time and in Figure 6 we see that Scenario-2 has 60% less CPU utilization.
Figure 5. Response Time (y Axis) Compared with the Number of Test Iterations (x Axis)

Figure 6. CPU Utilization of Scenario-1 as Compared with Scenario-2

While scale out is an important attribute of Java applications, when to scale up or scale out is key to any successful PaaS platform. On the one end of the spectrum, if every component of your system was wrapped in a service, and each service mapped to a single JVM, you would quickly find that a small system of 1000 components turns into a system of 1000 very small JVMs. What was formerly a call to another method or function within the same heap space is now remote, and you contend with the efficiency of your network. Your network will never be as fast as an in-memory call. Even in cases where there is a call to localhost (assuming the neighboring service is running on the same operating system), it might now be load balanced to some microservice a few hops away where it would hurt response time. This is why services, and the definition of services, must take into account the complete lifecycle of the service as driven by its transactional usage.
Transactions that traverse common services, all the time or during a majority of the time, must be as close to each other as possible, whereas if you assume that everything is remote in a soup of microservices hurts performance. Good PaaS platforms attempt to first provide a decent vertical heap size for your workload during incubation time (before you go live), and later allow you to adjust the configuration and decide when to scale up or scale out. In the background, the PaaS kernel attempts to vertically fill the NUMA socket of the physical server with either more JVM containers, if you chose to scale out, or with a smaller number of larger JVMs to the same net heap size.
Deciding between fewer larger JVMs and many smaller ones depends entirely on your workload. Mixing microservices of the same tenant onto the same JVM is relatively good practice as it allows for faster transactional response times. In the opposite case, mixing multitenant microservices would not be recommended because a multitenant JVM is not yet a mainstream approach. As we see multitenant JVMs become more common, we will start to see a shift in the market and in PaaS deployments towards larger JVMs, primarily because you can achieve greater performance at smaller infrastructure cost. The downside of course is that you have a larger JVM so if it crashes, you need to protect against the loss of a larger dataset or state.
PaaS platforms of the future should provide platform-based fault tolerance where deploying a service onto a JVM on a decent PaaS provides an option to have fault tolerance or redundancy. Of course this comes at a cost, and only those key state management services would be protected through this approach. PaaS platforms can certainly provide a mechanism that can copy the JVM memory state to a redundant copy at runtime to safety guard against failures. Whether this is done at the JVM, application container level, or VM level, or all of the above, is up to the PaaS platform engineer to decide. This is where cost, performance, and scalability drive a categorization of platform type dictated by the nature of the workload. In http://tinyurl.com/lrkhakf I discuss various categories of platforms, Category-1 web application based, and Category-2 in-memory database types of platforms. What you design for one might not be appropriate for the other.
4. Code Deployment and Flexibility Myths
The notion of independently deploying and updating a microservice independent of anything else around it has some practical limitations. Consider the soup of many microservices, perhaps multiple microservice instances of the same type. As an example, consider 3 main types, say 10 instances of Microservice1, 5 instances of Microservice 2, and 3 instances of Microservice 3. When you update a service definition, what happens to Microservice 1 and Microservice 2 while you are updating Microservice 3? How do you know which of the Microservice 1 and Microservice 2 instances must be quiesced, or told that the Microservice 3 instance they are about to access is going down? One answer is that it does not matter, but really this approach leads to a lot of transactional failures and its main issue is the fragmented complexity of not knowing the mesh graph of transactions.
In the case of the 25 REST services we discussed earlier, within the original model where every JVM had one type of REST service, the same problem existed of not being able to update a particular REST service type independent of the various other instances. Even if you could, it seems that you would have RESTService3 instance 1 with a newer version than the others. Perhaps you could hide this by not putting the updated service into the mix and rotate around and update the other instances in turn, but this requires a lot of coordination. Whereas in the case of having all of the REST services stacked onto one JVM, you can cleanly take out the entire JVM, and not that you would do this, but potentially you could have one JVM having an entirely newer REST service definition than the others, because the transactions do not cross to other JVMs.
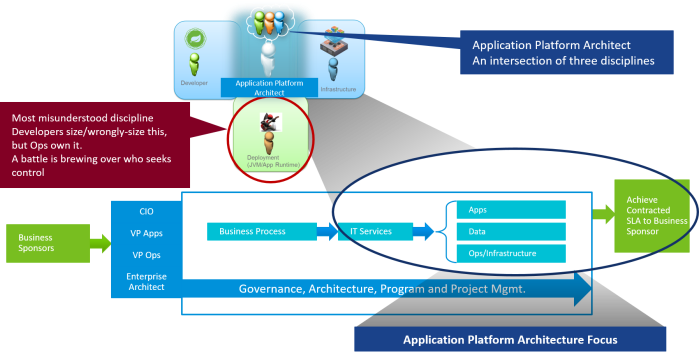
In my lucky career I spent the first 12 years as a pure software engineer coding lots of applications in C++ and Java. Since 2005 I have been delving more into platforms and infrastructure, which has given me the unique opportunity to fill the gap that exists in the area between the code and the infrastructure, an area I like to call application runtime, or application kernel.
I will write more about this, but in the meantime I think microservices are promising. However, they should not immediately imply micro-application kernels or JVMs. In some cases, a 1:1 ratio of microservices to JVMs might be excessive, but in other cases it is warranted.
There is quite a bit more to address on this topic, much of which is discussed in my book, http://tinyurl.com/lrkhakf.
Look for me at VMworld at this session: http://tinyurl.com/lnd5wpj